Your Data Isn't as Big as You Think
Here’s an uncomfortable truth: in most cases, you could throw away your Spark/Flink clusters and run the same queries on a single machine.
One of the most surprising findings I’ve seen shows that about 99% of real-world queries could fit entirely in memory on one box.
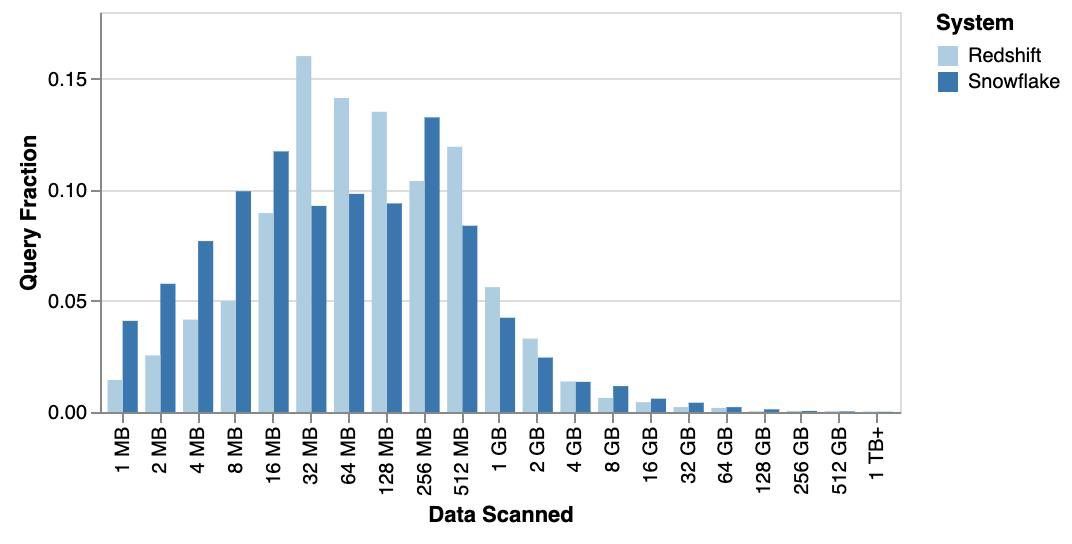
Why is that possible?
Despite the huge data lakes we all love to brag about, most queries only touch tiny slices of the data:
- The last hour
- A specific user segment
- Pre-aggregations you’ve already computed to boost performance
Yet the entire big data ecosystem assumes the opposite — that every query must be broken into pieces, shipped across a cluster, shuffled over the network, merged back, and only then returned.
And that’s a problem:
- Network shuffles kill performance
- They inflate infrastructure costs
- They overcomplicate systems
Meanwhile, modern CPUs (with SIMD and parallel execution) are so powerful that they blow past what most “distributed” systems can deliver on small-to-medium scale workloads.
A paradigm shift
This represents a fundamental shift in data engineering: when you stop moving data over the network, you don’t just save on cost and latency — you unlock optimizations that make things much faster.
It’s no wonder we’re starting to see movements around Small Data.
The right question to ask
Next time you reach for a “big data” system, ask yourself: Do you really have a big data problem? Or are you solving a small data problem with the wrong tool?